The robots.txt file is an essential component of web management that dictates how search engines interact with a website. This small but mighty text file, placed in the root directory of your website, serves as a communication tool between the site owner and search engine crawlers. By carefully controlling which parts of your site are accessible to these crawlers, you can optimize your site’s visibility in search engine results while ensuring that sensitive, outdated, or less relevant content remains untouched.
Understanding how to effectively leverage the robots.txt file is vital for anyone looking to enhance their site’s search engine optimization (SEO) strategy. Throughout this article, we will explore the intricacies of robots.txt, provide practical tips for optimizing it, and answer some of the most common questions related to its use. The goal is to arm you with the knowledge and tools you need to ensure that your website is indexed correctly and efficiently.
Table Of Contents
What is robots.txt?
At its core, robots.txt is a simple text file that follows the Robots Exclusion Protocol (REP), a standard utilized by search engines to dictate how their crawlers interact with websites. When search engine bots visit a website, they look for the robots.txt file to understand the rules governing their behavior on that particular site. This file outlines which pages or sections of the site should not be crawled or indexed, serving as a guideline for search engines like Google, Bing, and others.
Although this file does not prevent indexing of disallowed pages meaning that while the content may still appear in search results, it won’t be sourced from those specific pages it provides an essential layer of control over what crawlers can see and process. Thus, understanding the function and capabilities of the robots.txt file is fundamental for anyone managing a website, particularly those concerned about privacy, content relevance, and server performance.
Purpose of robots.txt
The primary purposes of the robots.txt file are diverse and vital for effective website management. First and foremost, it helps prevent the crawling of certain pages that may not be relevant for search engines or users, such as administrative areas, login pages, or staging versions of a site. By doing so, it not only protects sensitive content but also enhances the overall user experience by ensuring that search engines focus on the most important parts of your site.
Another key function is managing server load, particularly for larger websites with numerous pages. By limiting the areas that crawlers can access, you can reduce the number of requests your server handles, which is especially crucial during peak traffic periods.
Finally, robots.txt plays a role in controlling indexing; while it cannot prevent a page from being indexed, it can guide crawlers on which pages to prioritize for indexing, ultimately impacting your site’s visibility in search results. This multi-faceted utility underscores the importance of a well-structured robots.txt file in any digital strategy.
How to Create a robots.txt File
Creating a robots.txt file is a straightforward process, but it requires attention to detail to ensure that it functions correctly. Start by opening a simple text editor; options like Notepad, TextEdit, or any code editor will suffice. Once you have your editor open, the first step is to add user-agent directives that specify which web crawlers the rules will apply to. These directives help tailor the access rights based on the specific needs of your website.
After defining the user agents, you will need to include Disallow and Allow directives to indicate which pages or directories should be blocked from crawling or allowed for access. It’s crucial to save the file with the correct name, robots.txt, and place it in the root directory of your website, as this is the standard location where crawlers will look for it.
Lastly, before deploying your robots.txt file, it’s wise to test it using online validation tools to ensure that it is correctly formatted and effectively communicates your intended rules. This thorough approach will help you maximize the effectiveness of your robots.txt file and maintain control over how search engines interact with your site.
Example of a robots.txt File
To illustrate the structure and functionality of a robots.txt file, consider the following example:
User-agent: *
- This tells all web crawlers that the following rules apply to them.
Disallow Directives:
- Disallow: /private/
- This stops crawlers from going into the /private/ folder.
- This folder might have sensitive information that shouldn’t be public.
- Disallow: /temp/
- This stops crawlers from accessing the /temp/ folder.
- This area might contain temporary files that you want to keep hidden.
Allow Directive:
- Allow: /public/
- This lets crawlers index the /public/ folder.
- It makes sure that the content here is visible to search engines.
Overall Structure:
- This simple setup shows:
- How to direct crawlers on your site.
- How to control what gets indexed.
- The importance of keeping sensitive areas safe from unwanted access.
Understanding User-Agent
User-agents are unique identifiers used by web crawlers, and understanding them is crucial for optimizing your robots.txt file. Each search engine employs its own user-agent name to signify its crawling bots. For instance, Google utilizes “Googlebot,” Bing employs “Bingbot,” and Yahoo uses “Slurp.” By explicitly targeting specific user-agents within your robots.txt file, you can craft tailored rules that dictate how different search engines access your site.
This targeted approach allows for greater control over your site’s SEO performance, as you can restrict less important crawlers while allowing more significant ones to index essential content. For example, if you know that a specific crawler is causing excessive load on your server, you can block it without affecting others. Understanding user-agents not only helps in managing traffic effectively but also aids in optimizing your overall digital presence, ensuring that the most relevant content is prioritized by the right crawlers.
Common Directives in robots.txt
To effectively utilize robots.txt, it’s important to familiarize yourself with the common directives that can be employed to manage crawler behavior. Among the most critical directives are Allow, Disallow, User-agent, and Crawl-delay. The Allow directive is used to permit specific pages or directories, even when a broader Disallow rule exists, thereby granting selective access within a more restrictive context.
On the other hand, the Disallow directive instructs crawlers not to access specified pages or directories, effectively blocking them from indexing that content. The User-agent directive is pivotal as it specifies which web crawler the subsequent rules pertain to; using * applies the rules to all crawlers.
Additionally, the Crawl-delay directive, though not universally supported, can be employed to manage how frequently a crawler can access your site, which can be especially useful for reducing server load during peak times. Each of these directives plays a unique role in shaping how search engines interact with your site, and understanding them is essential for creating an effective robots.txt file.
Best Practices for Optimizing robots.txt
To maximize the effectiveness of your robots.txt file, several best practices should be adhered to. First and foremost, keeping the file simple is crucial. A straightforward robots.txt file is easier to manage and interpret, reducing the likelihood of errors or misconfigurations. Overly complex rules can lead to unintended consequences, so it’s best to avoid unnecessary complications.
Additionally, specific user-agent targeting can enhance your optimization efforts. By customizing rules for different crawlers, you can prioritize access for the most important search engines while limiting less relevant ones. Regular reviews and updates of your robots.txt file are also essential; as your website evolves, so too should your rules, ensuring they remain relevant and effective. Incorporating comments can further clarify your intentions within the file, making it easier for others, be they colleagues or future you, to understand the rationale behind your decisions.
Finally, always test your robots.txt file before deploying it live. Using online validators will help you catch formatting issues or errors that could hinder its performance. By following these best practices, you can ensure that your robots.txt file works effectively, guiding search engines in their interactions with your website.
Advanced Techniques for robots.txt
For those looking to take their robots.txt management to the next level, several advanced techniques can be employed. One of the most powerful options is the use of wildcards, which allow you to block multiple URLs that share a common pattern without needing to specify each one individually. For example, using Disallow: /temp/* effectively blocks all URLs that start with /temp/, streamlining your rules and enhancing clarity.
Another technique is to specify a crawl delay, which, although not universally recognized by all crawlers, can help manage the frequency with which they access your site. This can be particularly beneficial for larger sites or during periods of high traffic, allowing for better server performance. Furthermore, including a link to your sitemap in your robots.txt file can expedite the discovery of important pages by search engines.
By adding a line like Sitemap: https://www.example.com/sitemap.xml, you provide a clear pathway for crawlers to find your site’s key content quickly, improving the likelihood of effective indexing. These advanced techniques can significantly enhance how search engines perceive and interact with your site, ensuring that your optimization efforts yield the best possible results.
Common Mistakes to Avoid
When managing your robots.txt file, it’s crucial to be aware of common pitfalls that can undermine your efforts. One of the most significant mistakes is blocking essential pages inadvertently. It’s important to thoroughly review your robots.txt rules to ensure you don’t accidentally disallow critical pages such as your homepage or vital service pages that could negatively impact your SEO.
Additionally, failing to update your robots.txt file regularly can lead to lost traffic as your website evolves. Whenever you make significant changes to your site structure or content, revisiting your robots.txt is essential to ensure it accurately reflects those changes. Ignoring crawl errors is another misstep; monitoring your server logs for crawl errors and adjusting your robots.txt accordingly can help you avoid issues that might hinder your site’s performance.
Lastly, overusing the Disallow directive can be detrimental. While it’s important to protect certain content, blocking too many pages can hinder your SEO efforts by preventing search engines from indexing valuable information. By avoiding these common mistakes, you can maximize the effectiveness of your robots.txt file and maintain a healthy, well-indexed website.
FAQs
Can I submit robots.txt to Google Search?
Yes, you can submit your robots.txt file through Google Search Console. This allows Google to recognize your rules and directives. After making changes to your robots.txt, it’s a good idea to test it using the tools available in Search Console to ensure it’s working as intended.
How do you manually overwrite the robots.txt file in WordPress?
To overwrite the robots.txt file in WordPress, you can use an SEO plugin like Yoast SEO or All in One SEO. In these plugins, you can find the option to edit the robots.txt file directly. If you prefer manual methods, you can also create a robots.txt file using an FTP client or your hosting file manager and upload it to the root directory of your website.
How to disallow specific pages in Google robots.txt?
To disallow specific pages in your robots.txt, use the Disallow directive followed by the URL path. For example, to block access to a page called example-page, you would write:
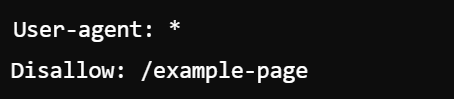
This tells all crawlers not to access that particular page.
How to block a spam domain in robots.txt?
You cannot directly block a spam domain from crawling your site using robots.txt. The robots.txt file controls how crawlers interact with your own site, not others. However, you can block specific crawlers you suspect are spam by using their user-agent. For example:

This blocks a bot named “SpamBot” from accessing any part of your site.
When should you use a robots.txt file?
You should use a robots.txt file when you want to control how search engines crawl your website. It’s particularly useful for:
- Protecting sensitive information.
- Reducing server load by limiting crawler access to certain pages.
- Improving SEO by guiding search engines to the most important content.
How to find robots.txt?
To find your robots.txt file, simply enter your website URL followed by /robots.txt in a web browser. For example, https://www.yourwebsite.com/robots.txt. If the file exists, it will display the contents.
How do I create a robots.txt file?
To create a robots.txt file, open a simple text editor (like Notepad). Write your desired directives (e.g., User-agent, Disallow, Allow) and save the file as robots.txt. Then, upload it to the root directory of your website using an FTP client or your hosting control panel.
How to edit robots.txt in WordPress?
To edit the robots.txt file in WordPress, you can use an SEO plugin like Yoast SEO. Navigate to the plugin settings, find the robots.txt editor, and make your changes there. If you don’t use a plugin, you can upload a new robots.txt file via FTP or your hosting file manager.
Conclusion
In conclusion, effectively managing your robots.txt file is essential for controlling how search engines interact with your website. By understanding its directives and properly configuring it, you can enhance your site’s visibility and protect sensitive content from unwanted access.
Regularly reviewing and updating your robots.txt file ensures that it aligns with your site’s evolving structure and goals. By following best practices and addressing common issues, you can optimize your website’s performance and improve your overall SEO strategy.
More From Our Blog
Page authority in SEO optimization
What do you need to balance when doing SEO optimization